
tl;dr: if you use BackBlaze and are subject to a data cap, you should keep an eye on BackBlaze to make sure it doesn’t quietly use up all your data allowance. I’ve switched to CrashPlan, which has better retention, encryption, and backup policies.
Beyond sharing this warning, I wanted to do a longer write-up of what I experienced because I found some pretty interesting things along the way – how to get true visibility into what’s happening on your local network, what’s up with Comcast’s usage meter, and what happens when something goes wrong with offsite backup with BackBlaze.
Earlier in the year Comcast announced they were introducing 1 terabyte data caps in 27 markets across the US (of which 18 previously did not have enforced caps). This is a pretty consumer-unfriendly move, and being in California this meant this was happening to me – but personally I had never come close to exceeding the cap, so wasn’t overly worried (and won’t be until 4K video becomes more common). In the second week of November 2016 I got a notification in my browser telling me I’d used 90% of my cap. This was surprising in two ways – one, I didn’t expect Comcast to hijack an http request to do this, and two, it was saying I’d used over 900gb of data in just over a week. I was about to head overseas for 8 days so I decided to shut everything down while I was away and figure out what was using the data once I got back.
While I was away, each day I saw my data continue to increase by approximately 80gb a day. I had a left my Mac Mini server running, a Dropcam, and a Nest and that was it. I checked remotely to ensure there were no other wireless clients running on my network, but couldn’t see anything. I used Activity Monitor to keep a track of how much bandwidth each process was using on the server, and saw BackBlaze (bztransmit) had transmitted ~50gb, but my uptime was 3 weeks at that point, and so that seemed about right. I was completely baffled – nothing else was being generated by the Mac Mini, and the amount of data uploaded by the Dropcam was also minimal, yet each day it kept increasing.
With no obvious culprits on my network, it seemed suspicious for me to be exceeding my cap just as they introduce caps, so my attention turned to whether Comcast’s usage reporting was accurate.
Comcast gets a lot of heat for their data caps, and in particular for their usage meter accuracy. When trying to use the meter to diagnose bandwidth issues, Comcast itself says it should not be relied on. They have a disclaimer on the meter saying it is “delayed by up to 24 hours” (and on the phone I was told it could lag for weeks). By the end of figuring all this out, I actually found their usage meter to be accurate in realtime, but others online report usage changing after the fact. I also found numerous people online complaining that their usage meter did not match their self-evaluated usage (some measured using tools such as using Gargoyle firmware on their router). However, most of these quibbles were off by 10% or so, not the orders of magnitude I was seeing. I was also unable to find well-proven cases of their meter being wildly off except for one instance where a MAC address had been entered with a single character typo. There was only one other example of Comcast rolling back fees for overages – but it only happened after the media became involved, and nobody technically proficient actually checked the network.
Given the likely accuracy, I was keen to find an inexpensive (and preferably software based, so I could do it remotely) method for measuring what was actually going through the cable modem. Most of the advice I found suggested buying a router that supported Gargoyle, but I also discovered that the Motorola SB6121 cable modem I use reports number of codewords per channel, aka bytes.
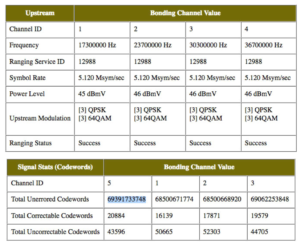
In the above example, you can see the aggregate codewords for the 4 channels is 275,455,328,290, which is 275.45 gigabytes. This was exactly as I would’ve expected. I remotely reset the cable modem (another quirk – Comcast removed the ability for me to do that myself on the cable modem through a modem update – I actually own the modem too) using the mobile app, and after doing so my traffic was measured in megabytes per day, which was what I expected. At this point I was baffled, as advice I’d seen repeated a few times online is to use the codewords as the source of truth, but they do NOT include uploads, which Comcast counts towards your cap.
At this point I didn’t know that, and since I had no idea how they were measuring so much traffic, I kept escalating with Comcast, eventually being told a level 3 support technician would contact me. That was a couple of weeks ago, and I never heard anything more from Comcast.
To be completely sure it wasn’t something on my end, my next step to diagnose this was to use SNMP logging to verify the amount of data leaving my network via the ethernet connection to the cable modem. SNMP is “simple network management protocol”, and is a standardized way of reporting and collating information about managed devices on a network. Routers with SNMP logging are able (amongst other things) to report exactly how much bandwidth is being consumed on any of its many interfaces (which are unhelpfully named, but a good description of each on an Airport Extreme is available here). Helpfully, mgi1 is the interface specifically for the WAN connection – i.e. I was able to measure very specifically every bit of traffic going to and from the cable modem. Unfortunately, Apple took this feature out of the 802.11ac Airport Extreme, which I used as my main router. As such I reconfigured my entire network to use my older router and an old Airport Express (which also includes SNMP logging).
At this point I had SNMP logging all my internal network bandwidth, and to visualize it I used PeakHour 3, which did a great job of making it very easy to see what was happening. At this point I finally had proof my Mac Mini really was uploading a LOT of data, and matched the Comcast usage. But Activity Monitor still did not show me that anything was out of sorts, so I still didn’t know WHAT was causing all the usage.
I researched what other tools I could use to monitor network traffic by process, and I found Little Snitch. Little Snitch lets you police all network requests, and approve or deny them, which is pretty nifty, but all I needed was the monitoring tool. This let me see that bztransmit was happily uploading at 5-10mbps in bursts every few minutes, and the cumulative from this process matched exactly the upload traffic seen in the SNMP logging. Leaving it for even just a few hours, it was clear this was the culprit.
I throttled BackBlaze using their preference pane to 128kbps (it claimed it would upload “approximately 1gb a day”, compared to the 4gb/hour it was doing at the time) and contacted their customer support. While I waited to hear back from them, I started reading through the BackBlaze log files, and saw it was uploading the same amount each day, and then a little more, e.g.:
server:bzreports_eventlog admin$ cat 10.log 2016-11-10 04:55:40 - END_BACKUP: Backed up 2801 FILES / 40617 MB server:bzreports_eventlog admin$ cat 17.log 2016-11-17 05:02:54 - END_BACKUP: Backed up 2933 FILES / 51489 MB
They helpfully have a log of the last files uploaded, located in /Library/Backblaze/bzdata/bzlogs/bzreports_lastfilestransmitted. The same files were being uploaded each day.
Another thing I noticed in the log files is that it appeared that BackBlaze was downloading updates and/or reinstalling itself basically every day. As far as I can tell, this was resetting the usage in Activity Monitor and why that was not a reliable measure.
While I was investigating these logs, I continued monitoring my network, and noticed that while BackBlaze was “throttled”, it ended up uploading nearly 4gb of data in 24 hours. The bztransmit process was using just under 1mbps of bandwidth, approximately 8x the promised throttle limit. To be clear, I have been using megabits for all my bandwidth measures in this post. I have to assume that there is a mistake in the conversion somewhere, which would perfectly explain why it was uploading at 128 KBps rather than Kbps. Their annotation in the UI and their documentation is ambiguous as it’s all lowercase and abbreviated, however, their estimates match that the numbers shown should be kilobits (128 kbps = 16 KBps = 1,382,400 kbytes = ~1.3GB/day).
BackBlaze got back to me the following day and asked for a copy of my logs – all of them. They gave me a unsigned tool which gathers all these logs, as well as a full system snapshot – approximately 50mb of log files in my case. At this point I wasn’t very comfortable about this. BackBlaze encrypts your files with your private key before uploading them, and according to an employee on Reddit, they can’t even see the filename. I really liked this feature – having all my private documents in the cloud is a scary proposition from a security perspective, and even if the contents are encrypted, the filename themselves leak entropy (e.g. financial documents, photo folder names, etc). I wasn’t particularly keen to send that over, as the logs are very chatty about your system and the files it’s working on.
At this point things with BackBlaze broke down. The customer support person I was communicating with ignored my request to surgically provide logs rather than send all of them. And by ignore, I mean they stopped updating the ticket and ignored my updates to the ticket. I was only able to re-engage them by pinging the BackBlaze Twitter account. He then refused to escalate further without the logs, and ignored my report of the throttling bug.
Without BackBlaze making any good faith efforts to remedy the situation (I should also note they were never apologetic about any of this, including just ignoring the ticket), I investigated alternatives, and have switched to CrashPlan. They offer a variety of better features compared to BackBlaze, including file versioning (including allowing deleted files to stay backed up – BackBlaze will delete after 30 days), 448-bit file encryption (versus 128-bit for BackBlaze), and allow NAS backups too. They are $60/year compared to $50/year for BackBlaze.
I had been using BackBlaze for 6 years. I had been an evangelist, recommending it to family and friends, and likely referred at least a dozen new customers to them. To say the least, I was very disappointed at this experience. After this happened, I did a quick look around to see if this had happened to others. What I found was a pattern of issues with customer support, slow restores, other bugs (folks missing files showed up several times), and backups being unexpectedly deleted from the server (e.g. someone goes on vacation and leaves their external drive at home, and while away the 30 day trigger hits. This also means if you do have a catastrophic data failure, you have 30 days to get your computer set up again to do a restore). It was interesting the different approaches people took to try to vent their issues with the company, including Amazon reviews, Facebook, the BBB and even CNet.
Most tellingly I found someone on Reddit reporting the same issue I encountered – a year ago – with other users in the thread reporting the same problems.
At the end of all this, I’ve spent somewhere in the vicinity of 20-30 hours of my time diagnosing this and talking with customer support, I’ve gone over my quota for two months (October and November – with the latter hitting 2TB in the end), leaving me a single courtesy month with Comcast (after which I never get any courtesy months again). On the plus side, my network is now more secure, and I learnt some interesting stuff along the way, and I was able to diagnose the cause literally 1 hour before midnight on November 30th, preventing me from going over again. The bummer is that there are two companies who have shown no interest in fixing issues for the consumer and puts all the onus on them: BackBlaze need to fix these bugs, and Comcast needs to provide their customers with better tools for diagnosing and monitoring network traffic if they’re going to institute caps for everyone.





 I got to borrow one of these from Google over Thanksgiving and I loved using it. It meant I had plenty to read while on vacation (where I get the bulk of my book-length reading done), without the bulk of the books. I bought Under The Dome by Stephen King recently, and wow, there’s a book that shows the utility of the Kindle (1074 pages).
I got to borrow one of these from Google over Thanksgiving and I loved using it. It meant I had plenty to read while on vacation (where I get the bulk of my book-length reading done), without the bulk of the books. I bought Under The Dome by Stephen King recently, and wow, there’s a book that shows the utility of the Kindle (1074 pages). RadRails is one of the few products where I’m not sure if it’s me at fault or them for not using it. As someone who got very comfortable in Eclipse and is a little lazy, I’d like to continue my Rails hacking in a familiar IDE. Unfortunately I just can’t seem to get RadRails to play nice with the latest releases of Ruby and RoR. When I get more time I’ll take another crack at it.
RadRails is one of the few products where I’m not sure if it’s me at fault or them for not using it. As someone who got very comfortable in Eclipse and is a little lazy, I’d like to continue my Rails hacking in a familiar IDE. Unfortunately I just can’t seem to get RadRails to play nice with the latest releases of Ruby and RoR. When I get more time I’ll take another crack at it.{kind=link}